SemEval 2025 Task 9: The Food Hazard Detection Challenge
The Food Hazard Detection task evaluates explainable classification systems for titles of food-incident reports collected from the web. These algorithms may help automated crawlers find and extract food issues from web sources like social media in the future. Due to the potential high economic impact, transparency is crucial for this task.
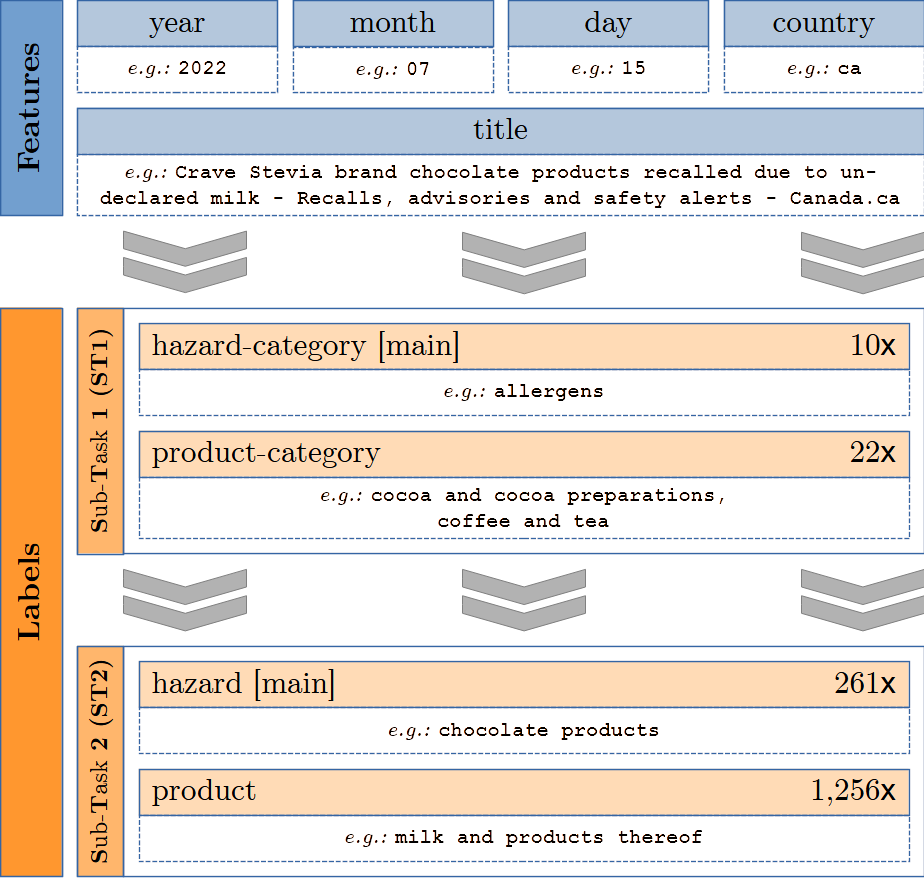
Figure 1: The blue boxes are model inputs; the orange boxes are ground truth labels per sub-task. The number on the right indicates unique values per label.
Figure 1 shows a sample of the dataset. The data features “year,” “month,” “day,” “country,” and “title”. Additionally, we provide the full text of the recall in the column “text.” Participants will base their analysis on either the “title” or the “text” feature (indicating which one they used). The task is to predict the labels “product-category” and “hazard-category” and the vectors “product” and “hazard.” The class distribution is heavily imbalanced. The data includes 1,142 different products (e.g., “ice cream,” “chicken based products,” “cakes”) sorted into 22 categories (e.g., “meat, egg and dairy products,” “cereals and bakery products,” “fruits and vegetables”). The 128 possible “hazard”-values (e.g., “salmonella,” “listeria monocytogenes,” “milk and products thereof”) are sorted into 10 “hazard-category” values.
The SemEval-Task combines two sub-tasks:
- (ST1) Text classification for food hazard prediction, predicting the type of hazard and product.
- (ST2) Food hazard and product “vector” detection, predicting the exact hazard and product.
The task focuses on detecting the hazard and uses a two-step scoring metric based on the macro F1 score, focusing on the hazard label per sub-task.
Task Organization
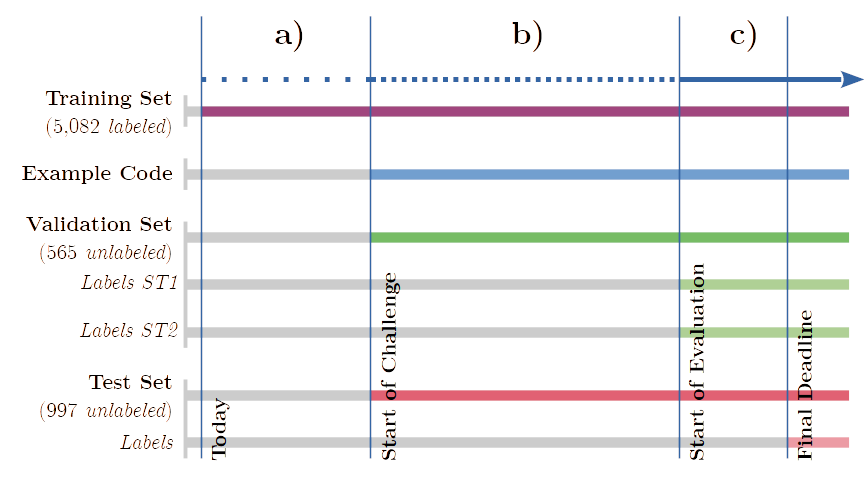
Figure 2: Challenge timeline: (a) Trial Phase; (b) Conception Phase; (c) Evaluation Phase.
The timeline is shown in Figure 2. Participants get training and validation data to build, train, and assess their systems before the evaluation period. The challenge takes place on Codalab and will be divided into four phases (all deadlines AoE time):
- Trial Phase (before September 2nd 2024)
- Labeled trial/training data (5,082 samples) are available for devising and training models.
- Conception Phase (September 2nd 2024 to January 10th 2025)
- Unlabeled validation data (565 samples) are released
- Unlabeled test data (997 samples) are released
- Codalab accepts separate trial submissions for ST1 (category classification) and ST2 (vector classification) on the validation data. Only the predictions in .csv format (zipped) will be uploaded.
- Evaluation Phase (January 10th 2025 to January 17th 2025)
- Labeled validation data (ST1 and ST2) are released
- Codalab accepts final submissions for both tasks on the test data. Only the predictions in .csv format (zipped) will be uploaded.
- Paper Phase (January 17th 2025 to February 28th 2025)
- Labeled test data (ST1 and ST2) are released
- Participants describe their systems in scientific papers and commit them to SemEval 2025
The two stages of the Conception Phase are intended to enable participants to compare their submission to each of the sub-tasks to other participants’ approaches. Therefore, we encourage uploading approaches for both sub-tasks of the conception phase to get a feel for the competition.
Explainability in food risk classification based on texts is currently underexplored although it may help humans quickly assess prediction validity and can be used for meta-learning approaches like clustering or pre-sorting examples. However, explanations can be diverse and task/model-dependent. Current literature includes both model-specific (Assael et al., 2022; Pavlopoulos et al., 2022) and model agnostic (Ribeiro et al., 2016) approaches. We aim to study mechanisms to explain decisions on food safety risks by asking participants to submit precise “vector”-labels (ST2) as explanations for their ST1 predictions.
Example code for this task can be found here.
Dataset

Figure 3: Sample texts with labels.
The dataset for this task consists of 6,644 short texts (length in characters: min=5, avg=88, max=277). Sample texts are shown in Figure 3. It includes manually labeled English food recall titles from official food agency websites (e.g., FDA). Each text is labeled by two food science or food technology experts. Upon task completion, the full dataset will be available under the Creative Commons BY-NC-SA 4.0 license on Zenodo.
Evaluation
We compute the performance for ST1 and ST2 by calculating the macro-F1-score on the participants’ predicted labels (hazards_pred & products_pred) using the annotated labels (hazards_true & products_true) as ground truth. The exact scoring function is provided here:
from sklearn.metrics import f1_score
def compute_score(hazards_true, products_true, hazards_pred, products_pred):
# compute f1 for hazards:
f1_hazards = f1_score(
hazards_true,
hazards_pred,
average='macro'
)
# compute f1 for products:
f1_products = f1_score(
products_true[hazards_pred == hazards_true],
products_pred[hazards_pred == hazards_true],
average='macro'
)
return (f1_hazards + f1_products) / 2.
With this measure, we base our rankings predominantly on the predictions for the hazard classes. Intuitively, this means that a submission with both hazards_pred and products_pred completely right will score 1.0, a submission with hazards_pred completely right and products_pred completely wrong will score 0.5, and any submission with hazards_pred completely wrong will score 0.0 independently of the value of products_pred.
Leaderboard
Here you can find the final leaderboard of the task:
Task Organizers
The organizers are:
- Korbinian Randl (lead) is a PhD student at Stockholm University. His research centers around machine learning for NLP and explainability. He works on applying these interests in food risk prediction.
- John Pavlopoulos (lead) is Assistant Professor at Athens University of Economics and Business and a lead researcher at Archimedes, Athena Research Center, Greece. He is also affiliated with Stockholm University and has co-organized BioASQ, HTREC, and SemEval Tasks 4 (2014) and 5 (2021).
- Aron Henriksson is an associate professor at Stockholm University working on machine learning for NLP in healthcare and education.
- Tony Lindgren is Stockholm University’s project leader for the EFRA project.
- Juli Bakagianni is an AI Research Associate at Agroknow, working on the EFRA project, where she focuses on NLP research to analyse and interpret data in alignment with the project’s objectives.
- Giannis Stoitsis is the CTO & Business Partner at Agroknow with extensive experience in developing advanced technologies for data aggregation and visualisation in the agricultural and food sectors.
You can contact the organizers using this email address.
Ethical statement
All texts come from official and publicly available sources, so no privacy issues are present. All annotations are provided by Agroknow experts. The systems are intended to complement but not substitute human experts in preventing illness or harm from food sources.
| This challenge is part of the EFRA project for Extreme Food Risk Analysis (funded by Horizon Europe under Grant Agreement No 101093026). Funded by the European Union. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or European Commission-EU. Neither the European Union nor the granting authority can be held responsible for them. |  |